Interpretable Deep Learning for Cervical Cancer Detection
Attention-Based Multiple Instance Learning (AB-MIL) on a Novel Pap Smear Dataset from Barishal Division.
Why This Matters
A Global Health Crisis
Cervical cancer remains one of the most preventable cancers, yet it continues to claim hundreds of thousands of lives. Early and accurate screening is the key — and AI can bridge the gap.
Among women aged 15–44 in 149 countries worldwide
Projected new cases with 411,000 deaths annually
Manual Pap tests are slow, variable, and face cytologist shortages
Gap in Existing Work
What Current Solutions Miss
Unrepresentative Datasets
Existing public datasets are lab-controlled, non-South Asian, and scarce in SCC cases.
Resolution Destruction
Standard CNN compression (4000×3000 → 224×224) destroys critical nuclear detail.
Black-Box Explanations
Grad-CAM produces unverifiable heatmaps — clinicians cannot trust black-box AI.
Classification Framework
The Bethesda System
Our model classifies Pap smear images across five clinically established Bethesda categories — from normal cytology to invasive carcinoma.
Normal
No abnormal cells detected. Healthy cytology with regular cell morphology.
Atypical Cells
Minor abnormalities of undetermined significance. Requires monitoring.
Low-Grade
Mild cytological changes, often HPV-related. Low-grade squamous intraepithelial lesion.
High-Grade
Severe pre-cancerous changes with high risk of progression to carcinoma.
Carcinoma
Invasive squamous cell carcinoma. Requires immediate clinical intervention.
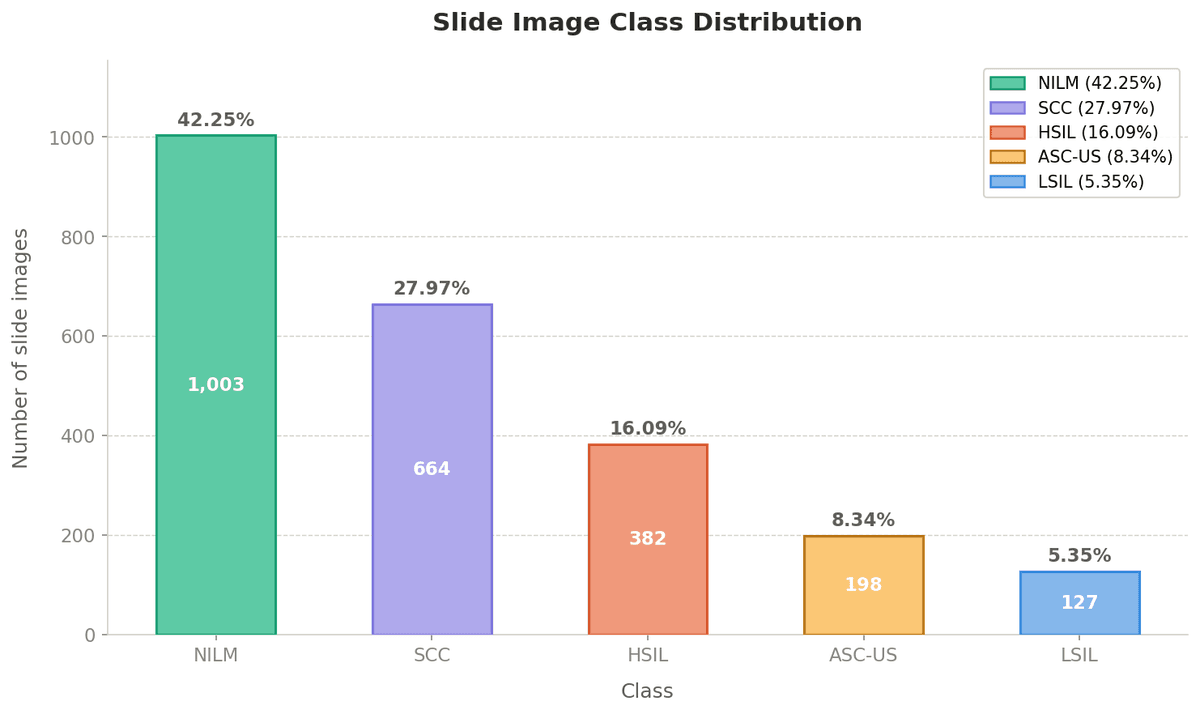
Data Collection & Curation
A Novel Dataset from Bangladesh
We curated the first and largest South Asian Pap smear FOV dataset — 2,374 images across 5 Bethesda classes, captured with a 40× Leica DM500 microscope at BRAC University lab.
Raw Collection
3,601 FOVs collected from SBMCH + private clinics, Barishal Division
Expert Annotation
2 expert pathologists annotated slides via a custom, secure web portal
Quality Curation
Cleanlab label-error removal → Entropy filtering → Stratified undersampling → 2,374 curated FOVs
Methodology
Why AB-MIL, Not Standard CNN?
Attention-Based Multiple Instance Learning (AB-MIL) enables interpretable, weakly-supervised classification at native resolution — without destroying critical nuclear morphology.
Weak Labels Only
Annotations are at the whole-FOV level — no cell-level ground truth available.
Segmentation Fails
Cellpose & StarDist fail on messy, overlapping cells in real clinical Pap smears.
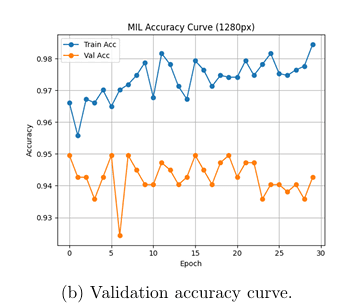
1280px Sweet Spot
Pilot study showed 1280px patches achieve 79.79% accuracy — best resolution/context tradeoff.
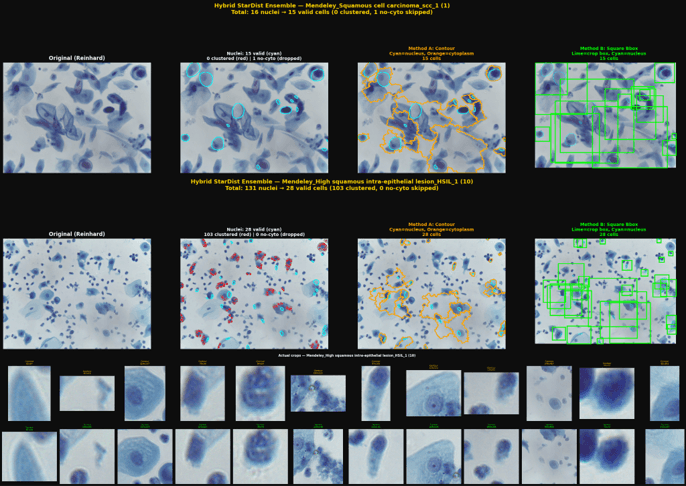
Patch Sample Visualizations
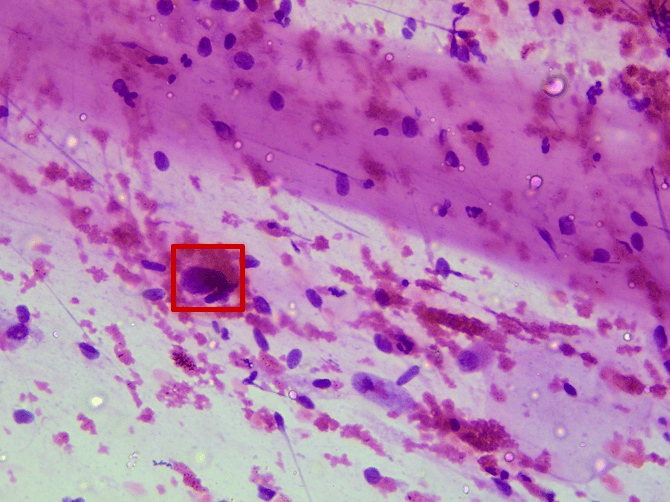
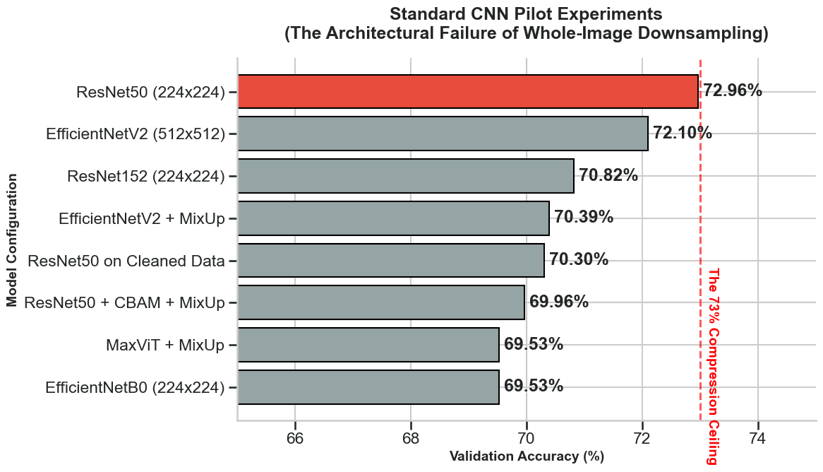
Patch Size vs. Accuracy Analysis
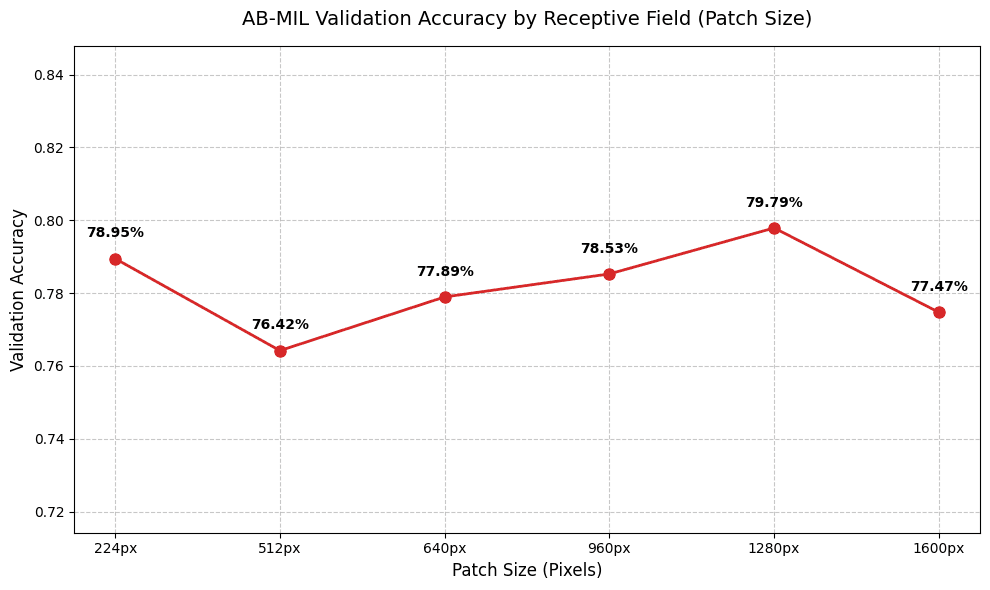
Note: 1280px achieved the highest pilot accuracy (79.79%), validating our patch strategy.
Model Architecture
Two-Phase Training Pipeline
Our model is trained in two distinct phases — first learning patch-level features with a ResNet50 backbone, then aggregating them with an attention mechanism to classify entire Pap smear fields of view.
Feature Extractor
AB-MIL Aggregator
Architecture Diagrams
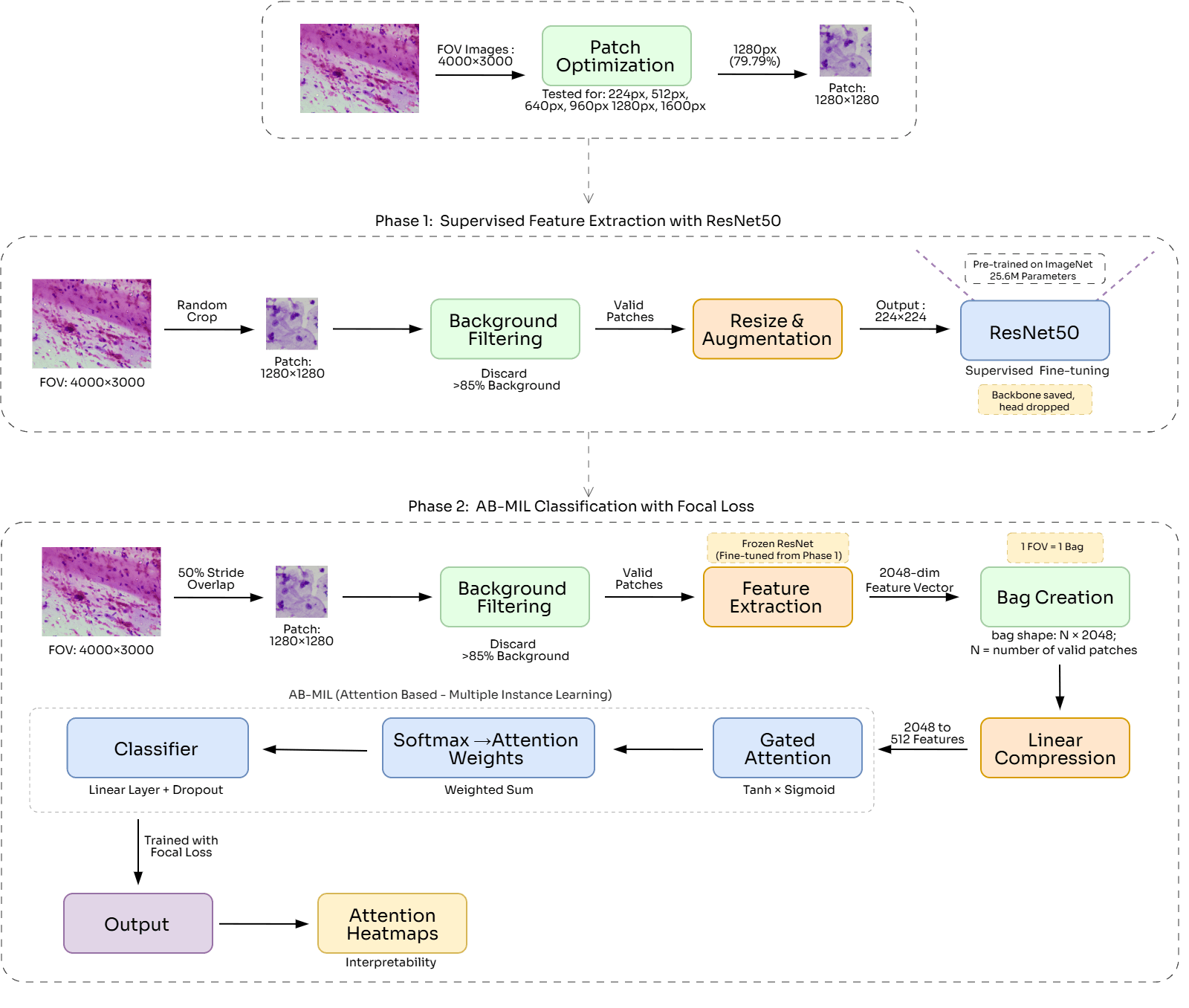
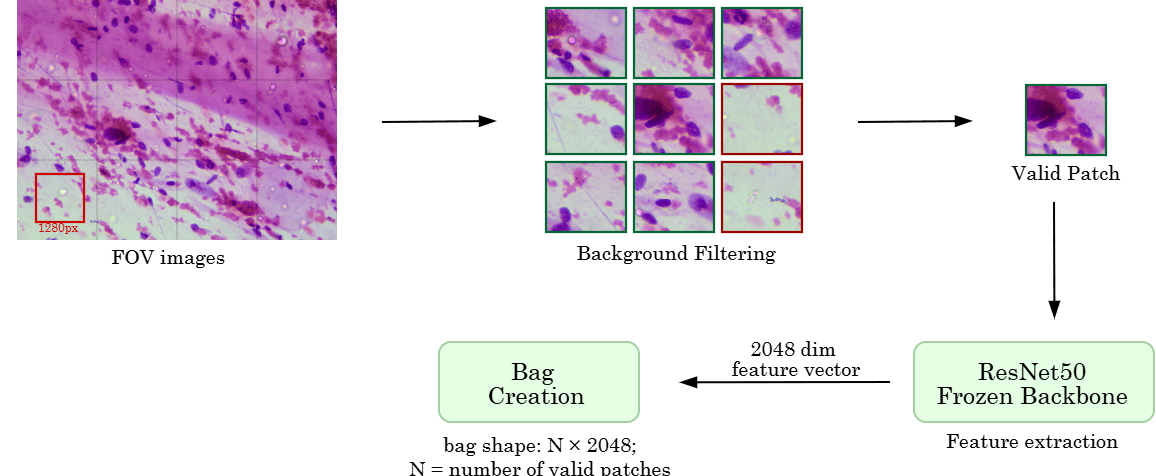
Interpretability
Native Attention Heatmaps
Unlike Grad-CAM, our attention weights use real spatial coordinates back-projected to the full 4000×3000 image — zero hallucination, zero guesswork. Clinicians can see exactly which cells the model attended to.
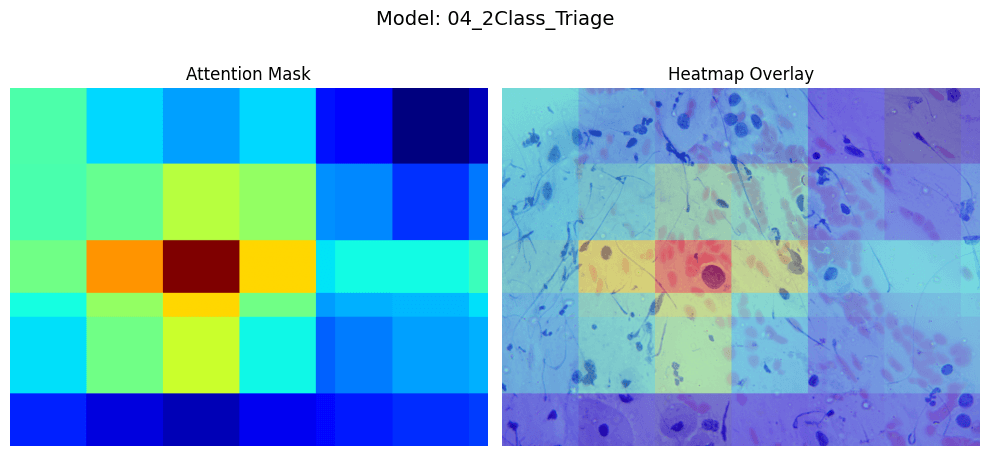
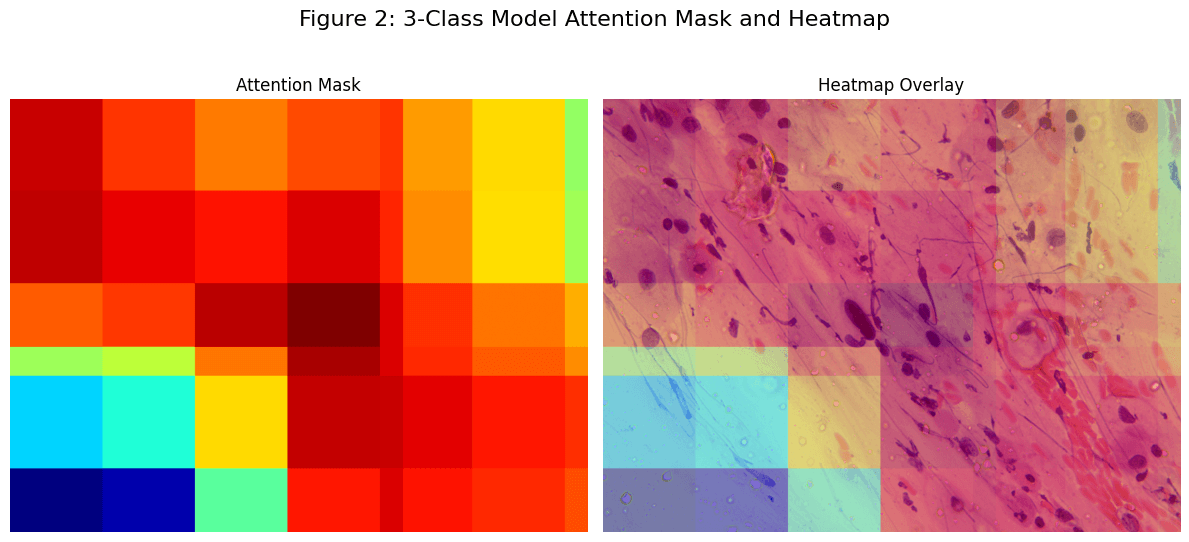
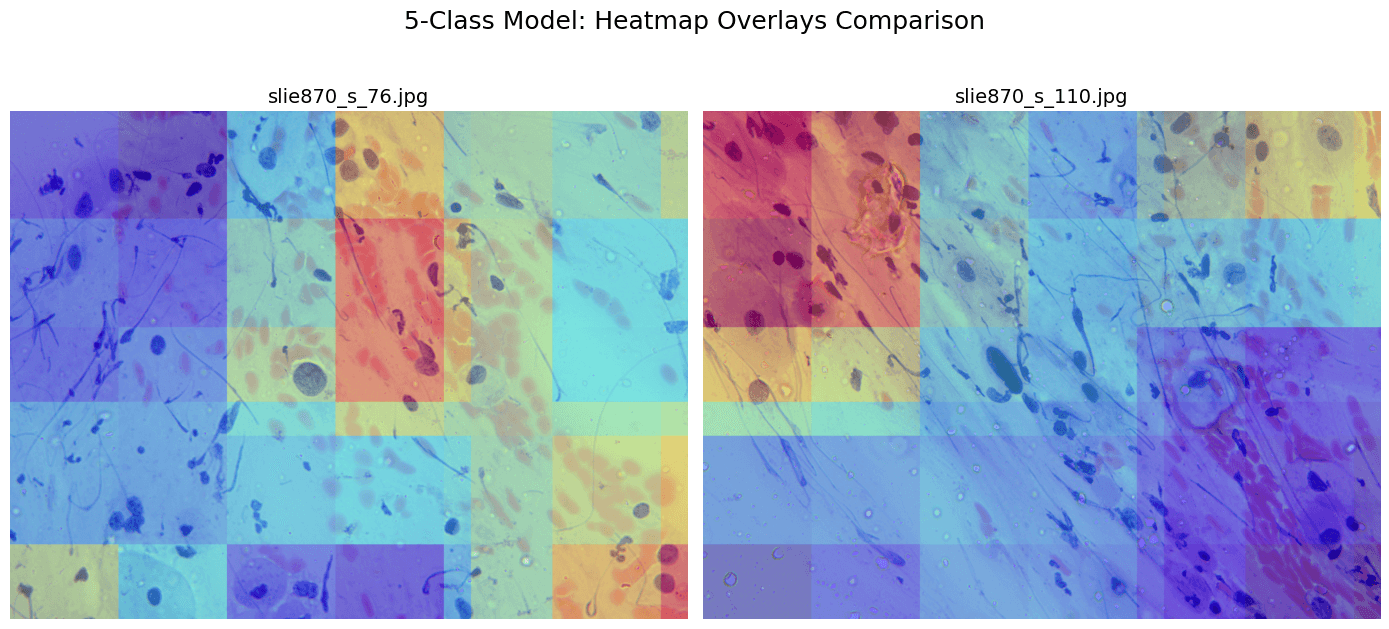
Experimental Results
State-of-the-Art Performance
Evaluated on n=475 test samples. Our AB-MIL model achieves clinical-grade sensitivity with zero critical misclassifications — a safety property standard CNNs cannot guarantee.
| Experiment | Accuracy | Notes |
|---|---|---|
| Binary Triage | 95% | AUC 0.99 · Sensitivity 97% |
| Strict Binary (No ASCUS) | 94.95% | AUC 0.99 |
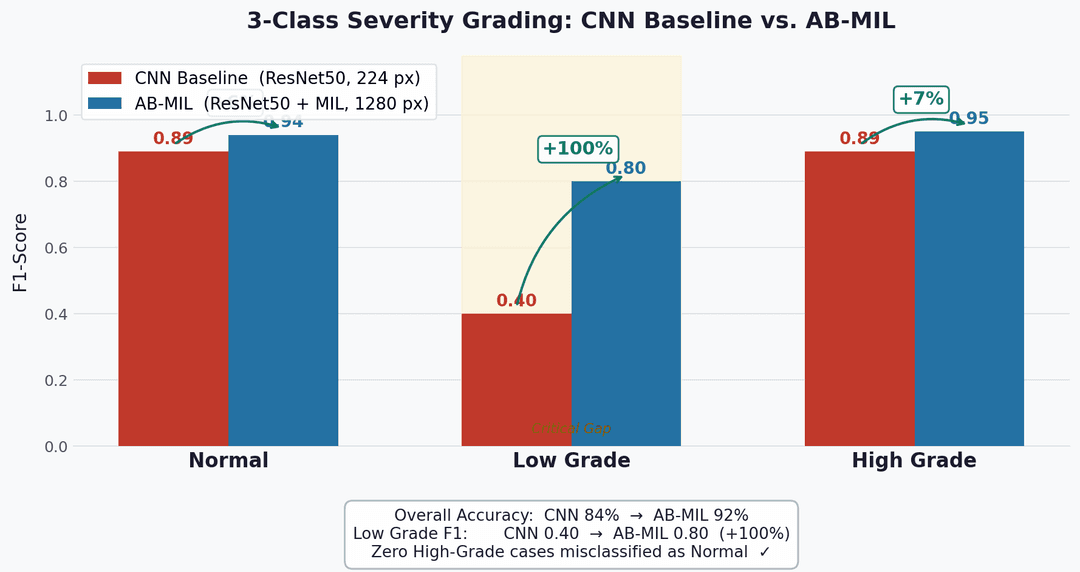
| 3-Class | 92% | 0 High-Grade → Normal errors |
| 5-Class | 81% | Best per-class F1 vs CNN |
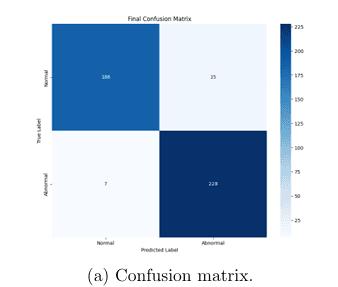
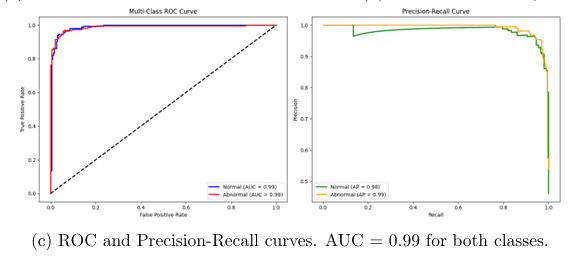
Visual Analysis
Visual Comparisons & AB-MIL vs CNN
Side-by-side comparisons of attention maps across cases demonstrate AB-MIL's superior localization ability and F1 score improvements over standard CNNs.
AB-MIL vs. Standard CNN — Performance Metrics
| Metric | AB-MIL | CNN |
|---|---|---|
| Low-Grade F1 | 0.80 | 0.40 |
| LSIL F1 | 0.43 | 0.29 |
| 3-Class Accuracy | 92% | 84% |
Key Achievements
What We Accomplished
First & Largest South Asian Pap Smear Dataset
2,374 curated FOV images across 5 Bethesda classes — a pioneering contribution to medical AI in Bangladesh.
95% Accuracy · 97% Sensitivity
Clinical-grade performance on binary triage with AUC of 0.99 — suitable for real-world screening assistance.
Zero Critical Misclassifications
Zero High-Grade → Normal errors in the 3-class model — a critical safety property for clinical deployment.
Limitations & Future Work
Honest Assessment & Next Steps
Overfitting on 5-Class
The 5-class configuration shows overfitting tendencies due to dataset size limitations.
Larger dataset collection + advanced augmentation strategies
Class Imbalance
ASCUS and LSIL classes remain underrepresented even after stratified undersampling.
Synthetic data generation (GAN-based) for minority classes
Fine-Grained 5-Class Boundaries
Subtle morphological differences between adjacent Bethesda classes remain challenging.
Multi-scale attention + expert curriculum learning
Project Gallery
Behind the Research
A glimpse into the months of lab work, clinical collaboration, and dedication that went into building this thesis from the ground up.





The Team